
„Гато“ на DeepMind е просечен, па зошто го изградија?


Невралната мрежа „Gato“ на DeepMind се истакнува во бројни задачи, вклучително и контролирање на роботски раце што натрупуваат блокови, играње игри на Atari 2600 и пишување слики.
Deepmind
Светот е навикнат да гледа наслови за најновото откритие со длабоко учење форми на вештачка интелигенција. Најновото достигнување на одделот на Google DeepMind, сепак, може да се сумира како: „Една програма за вештачка интелигенција која прави толку работа во многу работи“.
Популарно сега
Гато, како што се нарекува програмата на DeepMind, беше претставен оваа недела како таканаречена мултимодална програма, програма која може да игра видео игри, да разговара, да пишува композиции, да титлува слики и да контролира роботски блокови за натрупување на рацете. Тоа е една невронска мрежа која може да работи со повеќе видови податоци за да извршува повеќе видови задачи.
„Со еден сет на тегови, Гато може да се вклучи во дијалог, да титлува слики, да натрупува блокови со вистинска рака на робот, да ги надмине луѓето во играњето игри на Atari, да се движи во симулирани 3D средини, да ги следи упатствата и многу повеќе“, напиша главниот автор Скот Рид. и колегите во нивниот труд, „Генералистички агент“, објавено на серверот за предпечатење Arxiv.
Коосновачот на DeepMind Демис Хасабис го бодреше тимот, извикува во твит, „Нашиот најопшт агент досега!! Фантастична работа од тимот!“
Значи: Нов експеримент: Дали вештачката интелигенција навистина знае мачки или кучиња - или нешто друго?
Единствениот улов е што Гато всушност не е толку одличен за неколку задачи.
Од една страна, програмата може подобро од посветената програма за машинско учење во контролирањето на роботската Соерова рака која натрупува блокови. Од друга страна, создава натписи за слики кои во многу случаи се прилично лоши. Неговата способност за стандарден разговор со човечки соговорник е слично медиокритетна, понекогаш предизвикувајќи контрадикторни и бесмислени искази.
И неговото играње на Atari 2600 видео игри е под онаа на повеќето посветени ML програми дизајнирани да се натпреваруваат во репер Аркадна средина за учење.
Популарно сега
Зошто би направиле програма која прави некои работи прилично добро, а еден куп други работи не толку добро? Преседан и очекување, според авторите.
Постои преседан за поопшти видови програми да станат најсовремена технологија во вештачката интелигенција и постои очекување дека зголемените количини на компјутерска моќ во иднина ќе ги надоместат недостатоците.
Генералноста може да има тенденција да триумфира во вештачката интелигенција. Како што забележуваат авторите, цитирајќи го научникот за вештачка интелигенција Ричард Сатон, „Историски гледано, генеричките модели кои се подобри во искористувањето на пресметките, исто така, имаат тенденција да ги надминат поспецијализираните пристапи специфични за доменот на крајот“.
Како што напиша Сатон во својот блог пост„Најголемата лекција што може да се прочита од 70-годишното истражување на вештачката интелигенција е дека општите методи кои го користат пресметувањето се на крајот најефективни и со голема разлика.
Во формална теза, Рид и тимот пишуваат дека „ние овде ја тестираме хипотезата дека е возможно да се обучи агент кој е генерално способен за голем број задачи; и дека овој генерален агент може да се прилагоди со малку дополнителни податоци за да успее во уште поголем број задачи“.
Значи: Светлото за вештачка интелигенција LeCun на Мета ја истражува енергетската граница на длабокото учење
Моделот, во овој случај, е навистина многу општ. Тоа е верзија на Transformer, доминантен вид модел базиран на внимание што стана основа на бројни програми вклучувајќи го и GPT-3. Трансформаторот ја моделира веројатноста за некој елемент со оглед на елементите што го опкружуваат како што се зборовите во реченицата.
Во случајот со Гато, научниците од DeepMind можат да го користат истото условно пребарување на веројатност на бројни типови податоци.
Како што Рид и неговите колеги ја опишуваат задачата да го тренираат Гато,
За време на фазата на обука на Гато, податоците од различни задачи и модалитети се серијализираат во рамна секвенца од токени, групирани и обработени од трансформаторска невронска мрежа слична на голем јазичен модел. Загубата е маскирана така што Гато предвидува само цели за акција и текст.
Гато, со други зборови, не ги третира токените поинаку без разлика дали се тие зборови во разговорот или вектори на движење во вежба за натрупување блокови. Се е исто.
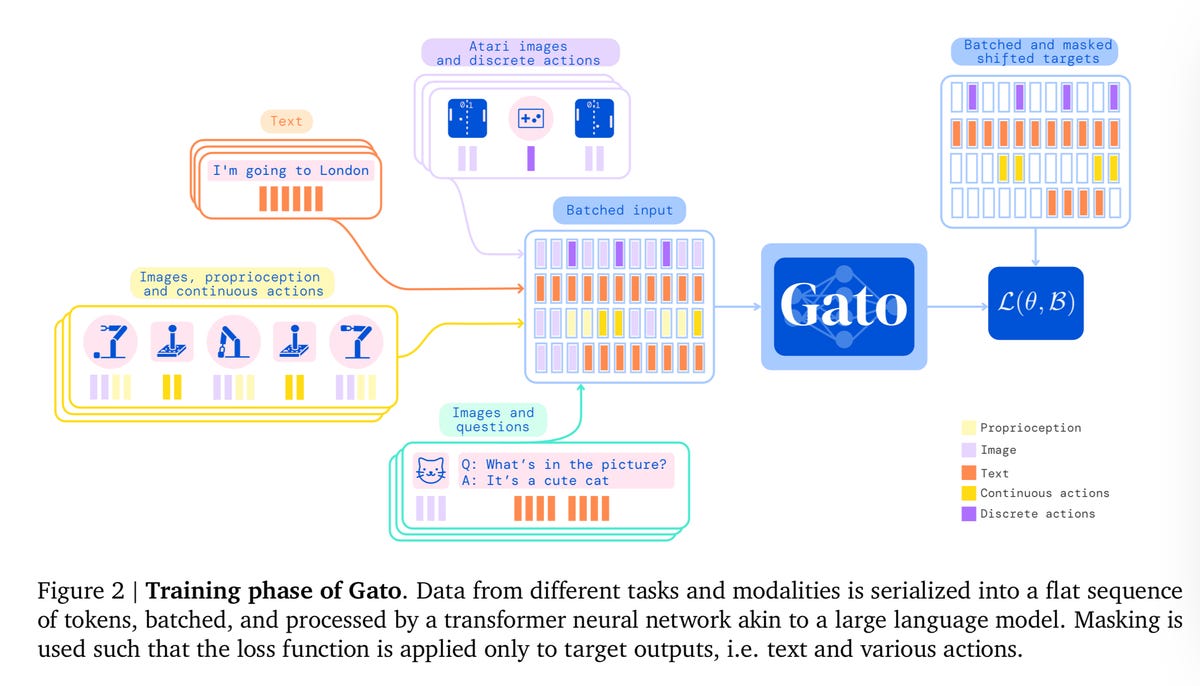
Сценарио за тренирање Гато.
Рид и сор. 2022 година
Закопана во хипотезата на Рид и тимот е последица, имено дека на крајот ќе победи се повеќе и повеќе компјутерска моќ. Во моментов, Гато е ограничен со времето на одговор на роботската рака на Соер што го прави редење блокови. Со 1.18 милијарди мрежни параметри, Gato е многу помал од многу големите модели со вештачка интелигенција како што е GPT-3. Како што моделите за длабоко учење стануваат се поголеми, изведувањето заклучоци доведува до латентност што може да пропадне во недетерминистичкиот свет на роботот од реалниот свет.
Но, Рид и неговите колеги очекуваат таа граница да биде надмината бидејќи хардверот со вештачка интелигенција станува побрз во обработката.
„Го фокусираме нашиот тренинг на оперативната точка на скалата на моделот што овозможува контрола во реално време на роботите од реалниот свет, моментално околу 1.2B параметри во случајот со Гато“, напишаа тие. „Како што се подобруваат архитектурите на хардверот и моделите, оваа оперативна точка природно ќе ја зголеми изводливата големина на моделот, туркајќи ги генералистичките модели повисоко во кривата на законот за скалирање“.
Оттука, Гато е навистина модел за тоа како скалата на пресметување ќе продолжи да биде главниот вектор на развојот на машинското учење, со тоа што општите модели ќе бидат поголеми и поголеми. Поголемото е подобро, со други зборови.
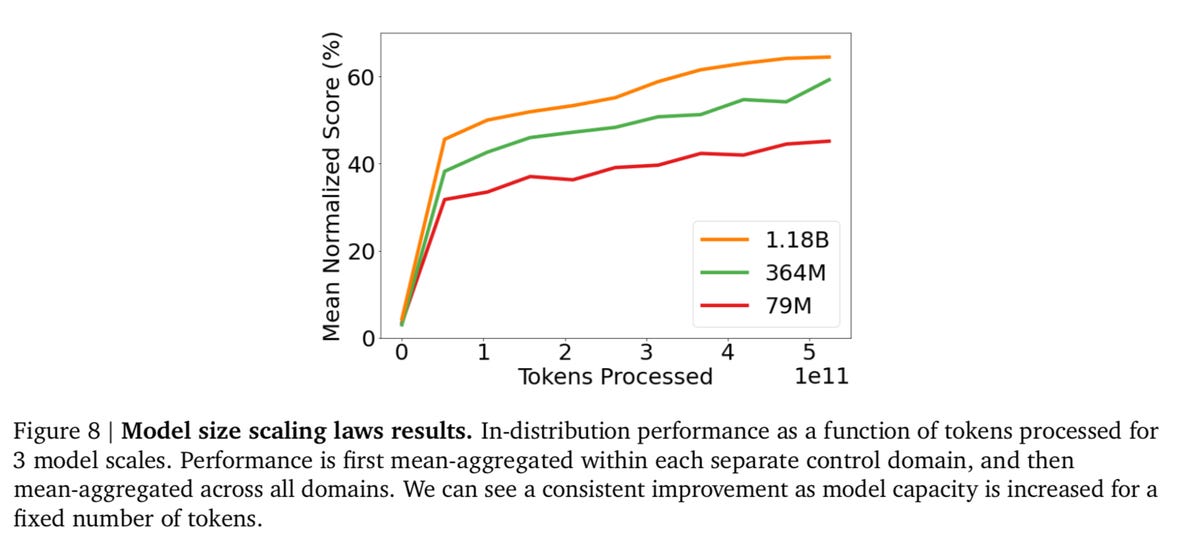
Гато станува подобар како што се зголемува големината на невронската мрежа во параметри.
Рид и сор. 2022 година
И авторите имаат некои докази за ова. Гато се чини дека станува подобар како што станува поголем. Тие ги споредуваат просечните оценки за сите репер задачи за три големини на модел според параметрите, 79 милиони, 364 милиони и главниот модел, 1.18 милијарди. „Можеме да видиме дека за еквивалентно броење на токени, има значително подобрување на перформансите со зголемен обем“, пишуваат авторите.
Интересно идно прашање е дали програма која е генералист е поопасна од другите видови програми за вештачка интелигенција. Авторите поминуваат многу време во трудот дискутирајќи за фактот дека постојат потенцијални опасности кои сè уште не се добро разбрани.
Идејата за програма која се справува со повеќе задачи му сугерира на лаик еден вид човечка приспособливост, но тоа може да биде опасна погрешна перцепција. „На пример, физичкото отелотворување може да доведе до тоа корисниците да го антропоморфизираат агентот, што ќе доведе до погрешна доверба во случај на неисправен систем или да биде искористлив од лоши актери“, пишуваат Рид и тимот.
„Дополнително, додека трансферот на знаење меѓу домени често е цел во истражувањето за ML, тоа може да создаде неочекувани и несакани резултати доколку одредени однесувања (на пр. борба со аркадни игри) се пренесат во погрешен контекст“.
Оттука, тие пишуваат: „Етичките и безбедносните размислувања за пренос на знаење може да бараат значителни нови истражувања како што напредуваат генералистичките системи“.
(Како интересна споредна забелешка, трудот Гато користи шема за опишување на ризикот, смислен од поранешната истражувачка на Google AI, Маргарет Мишел и колегите, наречена Model Cards. Model Cards даваат концизен преглед за тоа што е програма за вештачка интелигенција, што прави и што Фактори влијаат на тоа како функционира. Мишел минатата година напиша дека била принудена да го напушти Google поради поддршката на нејзиниот поранешен колега, Тимнит Гебру, чии етички грижи за вештачката интелигенција наиде на лидерство со вештачка интелигенција на Google.)
Гато во никој случај не е единствен во својата генерализирачка тенденција. Тоа е дел од широкиот тренд на генерализација и поголемите модели кои користат кофи со коњски сили. Светот го доби првиот вкус на наклонетоста на Google во оваа насока минатото лето, со невронската мрежа „Perceiver“ на Google која комбинираше текстуални задачи на трансформатор со слики, звук и просторни координати LiDAR.
Значи: Супермоделот на Google: DeepMind Perceiver е чекор на патот кон машина за вештачка интелигенција која може да обработи се и сешто
Меѓу неговите врсници е PaLM, јазичниот модел на Pathways, претставена оваа година од научниците на Google, модел со параметри од 540 милијарди кој користи нова технологија за координирање на илјадници чипови, познати како Патеки, исто така измислен во Google. Невралната мрежа објавена во јануари од Мета, наречена „data2vec“, користи трансформатори за податоци за слики, говорни аудио бранови форми и репрезентации на текстуален јазик, сите во едно.
Она што е ново за Гато, се чини, е намерата да се земе вештачката интелигенција што се користи за не-роботски задачи и да се турне во сферата на роботиката.
Креаторите на Гато, забележувајќи ги достигнувањата на Pathways и другите генералистички пристапи, го гледаат крајното достигнување во вештачката интелигенција што може да работи во реалниот свет, со секаков вид задачи.
„Идната работа треба да размисли како да се обединат овие способности на текстот во еден целосно генералистички агент кој исто така може да дејствува во реално време во реалниот свет, во различни средини и отелотворувања“.
Тогаш, можете да го сметате Гато како важен чекор на патот кон решавање на најтешкиот проблем на вештачката интелигенција, роботиката.
