
'Gato' của DeepMind tầm thường, vậy tại sao họ lại xây dựng nó?


Mạng thần kinh “Gato” của DeepMind vượt trội trong nhiều nhiệm vụ, bao gồm điều khiển cánh tay robot xếp chồng các khối, chơi trò chơi Atari 2600 và tạo chú thích cho hình ảnh.
Deepmind
Thế giới đã quen với việc nhìn thấy những tiêu đề về bước đột phá mới nhất của các hình thức học sâu của trí tuệ nhân tạo. Tuy nhiên, thành tựu mới nhất của bộ phận DeepMind của Google có thể được tóm tắt là “Một chương trình AI thực hiện được rất nhiều công việc.”
Phổ biến ngay bây giờ
Gato, tên chương trình của DeepMind, đã được ra mắt trong tuần này như một chương trình được gọi là đa phương thức, một chương trình có thể chơi trò chơi điện tử, trò chuyện, viết tác phẩm, chú thích ảnh và điều khiển các khối xếp chồng cánh tay robot. Đó là một mạng lưới thần kinh có thể hoạt động với nhiều loại dữ liệu để thực hiện nhiều loại nhiệm vụ.
Tác giả chính Scott Reed viết: “Với một bộ trọng lượng duy nhất, Gato có thể tham gia vào cuộc đối thoại, chú thích hình ảnh, xếp các khối bằng cánh tay robot thực sự, chơi trò chơi Atari tốt hơn con người, điều hướng trong môi trường 3D mô phỏng, làm theo hướng dẫn và hơn thế nữa”. và các đồng nghiệp trong bài báo của họ, “A Generalist Agent,” được đăng trên máy chủ in sẵn Arxiv.
Người đồng sáng lập DeepMind, Demis Hassabis đã cổ vũ cho đội: kêu lên trong một tweet, “Đại lý chung nhất của chúng tôi!! Công việc tuyệt vời của nhóm!
Ngoài ra: Một thử nghiệm mới: AI có thực sự biết mèo, chó hay bất cứ thứ gì không?
Điều đáng chú ý duy nhất là Gato thực sự không giỏi trong một số nhiệm vụ.
Một mặt, chương trình có thể hoạt động tốt hơn một chương trình học máy chuyên dụng trong việc điều khiển cánh tay robot Sawyer xếp các khối. Mặt khác, nó tạo ra chú thích cho hình ảnh mà trong nhiều trường hợp khá kém. Khả năng đối thoại trò chuyện tiêu chuẩn với người đối thoại của nó cũng ở mức tầm thường tương tự, đôi khi gợi ra những phát ngôn mâu thuẫn và vô nghĩa.
Và việc chơi trò chơi điện tử Atari 2600 của nó thấp hơn so với hầu hết các chương trình ML chuyên dụng được thiết kế để cạnh tranh trong tiêu chuẩn Môi trường học tập Arcade.
Phổ biến ngay bây giờ
Tại sao bạn lại tạo một chương trình thực hiện một số thứ khá tốt và một loạt thứ khác không tốt lắm? Tiền lệ và kỳ vọng, theo các tác giả.
Đã có tiền lệ về việc các loại chương trình tổng quát hơn sẽ trở thành công nghệ tiên tiến trong AI và người ta kỳ vọng rằng việc tăng cường sức mạnh tính toán trong tương lai sẽ bù đắp cho những thiếu sót.
Tính tổng quát có thể có xu hướng chiến thắng trong AI. Như các tác giả lưu ý, trích dẫn học giả AI Richard Sutton, “Về mặt lịch sử, các mô hình chung có khả năng tận dụng tính toán tốt hơn cũng có xu hướng vượt qua các phương pháp tiếp cận theo miền cụ thể chuyên biệt hơn”.
Như Sutton đã viết trong bài viết blog của riêng mình“Bài học lớn nhất có thể rút ra từ 70 năm nghiên cứu AI là các phương pháp chung tận dụng khả năng tính toán cuối cùng là hiệu quả nhất và đạt được hiệu quả lớn.”
Đưa vào một luận điểm chính thức, Reed và nhóm viết rằng “ở đây chúng tôi kiểm tra giả thuyết rằng việc đào tạo một đặc vụ thường có khả năng thực hiện một số lượng lớn nhiệm vụ là có thể thực hiện được; và rằng tổng đại lý này có thể được điều chỉnh với ít dữ liệu bổ sung để thành công ở số lượng nhiệm vụ lớn hơn.”
Ngoài ra: Meta AI sáng chói LeCun khám phá biên giới năng lượng của học sâu
Mô hình trong trường hợp này thực sự rất chung chung. Nó là phiên bản của Transformer, loại mô hình dựa trên sự chú ý chiếm ưu thế đã trở thành nền tảng của nhiều chương trình bao gồm GPT-3. Một máy biến áp mô hình hóa xác suất của một số phần tử dựa trên các phần tử bao quanh nó, chẳng hạn như các từ trong câu.
Phổ biến ngay bây giờ
Trong trường hợp của Gato, các nhà khoa học DeepMind có thể sử dụng cùng một cách tìm kiếm xác suất có điều kiện trên nhiều loại dữ liệu.
Như Reed và các đồng nghiệp mô tả nhiệm vụ huấn luyện Gato,
Trong giai đoạn đào tạo của Gato, dữ liệu từ các nhiệm vụ và phương thức khác nhau được tuần tự hóa thành một chuỗi mã thông báo phẳng, được phân nhóm và xử lý bởi mạng thần kinh biến áp tương tự như mô hình ngôn ngữ lớn. Sự mất mát được che giấu để Gato chỉ dự đoán các mục tiêu hành động và văn bản.
Nói cách khác, Gato không xử lý mã thông báo một cách khác biệt cho dù chúng là các từ trong cuộc trò chuyện hay vectơ chuyển động trong bài tập xếp khối. Tất cả đều giống nhau.
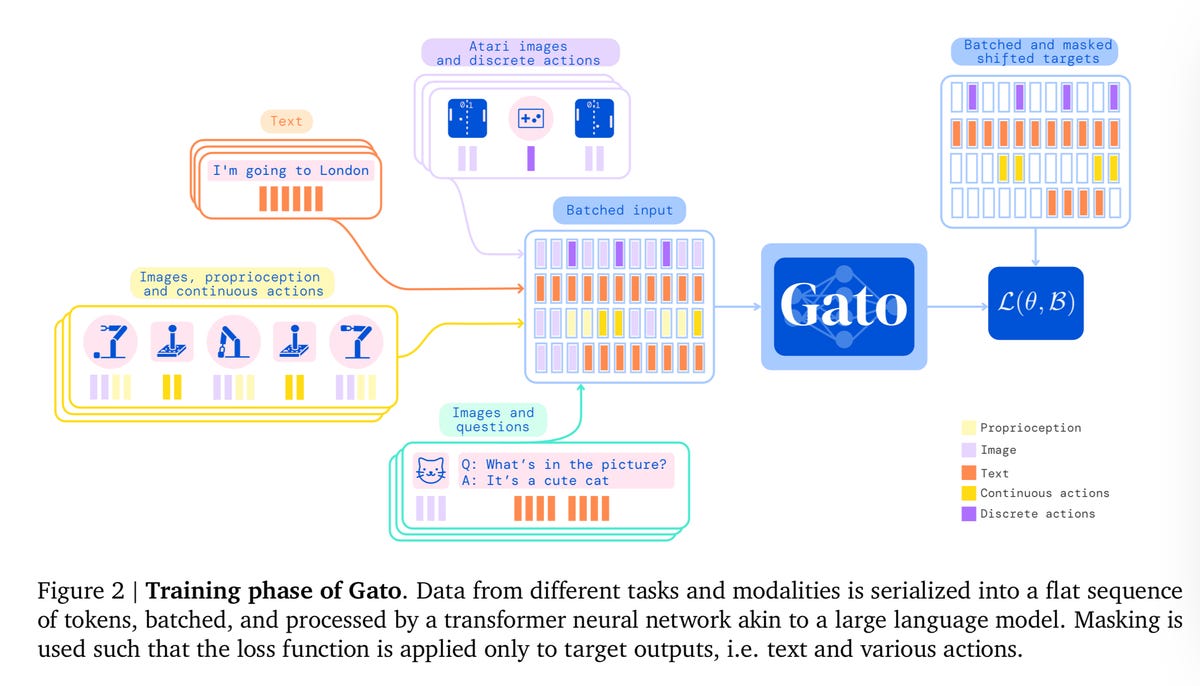
Kịch bản đào tạo Gato.
Sậy và cộng sự. 2022
Bị chôn vùi trong giả thuyết của Reed và nhóm là một hệ quả tất yếu, đó là cuối cùng thì ngày càng nhiều sức mạnh tính toán sẽ giành chiến thắng. Hiện tại, Gato bị giới hạn bởi thời gian phản hồi của cánh tay robot Sawyer thực hiện việc xếp chồng khối. Với 1.18 tỷ thông số mạng, Gato nhỏ hơn rất nhiều so với các mô hình AI rất lớn như GPT-3. Khi các mô hình học sâu ngày càng lớn hơn, việc thực hiện suy luận dẫn đến độ trễ có thể thất bại trong thế giới không xác định của robot trong thế giới thực.
Phổ biến ngay bây giờ
Tuy nhiên, Reed và các đồng nghiệp hy vọng giới hạn đó sẽ bị vượt qua khi phần cứng AI xử lý nhanh hơn.
Họ viết: “Chúng tôi tập trung đào tạo vào điểm vận hành của quy mô mô hình cho phép điều khiển thời gian thực của robot trong thế giới thực, hiện có khoảng 1.2B thông số trong trường hợp của Gato”. “Khi kiến trúc phần cứng và mô hình được cải thiện, điểm vận hành này sẽ tự nhiên tăng kích thước mô hình khả thi, đẩy các mô hình tổng quát lên cao hơn trên đường cong quy luật mở rộng.”
Do đó, Gato thực sự là một mô hình cho thấy quy mô tính toán sẽ tiếp tục là hướng phát triển chính của máy học như thế nào, bằng cách làm cho các mô hình chung ngày càng lớn hơn. Nói cách khác, lớn hơn là tốt hơn.
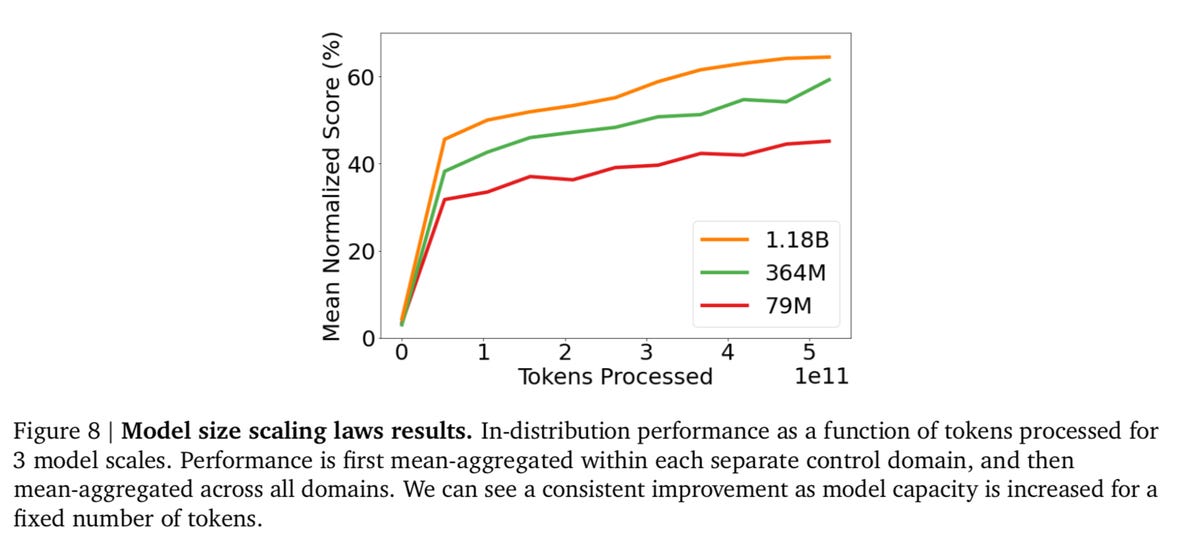
Gato trở nên tốt hơn khi kích thước của mạng lưới thần kinh trong các tham số tăng lên.
Sậy và cộng sự. 2022
Và các tác giả có một số bằng chứng cho điều này. Gato dường như trở nên tốt hơn khi nó lớn hơn. Họ so sánh điểm trung bình trên tất cả các nhiệm vụ chuẩn cho ba kích thước của mô hình theo thông số, 79 triệu, 364 triệu và mô hình chính, 1.18 tỷ. Các tác giả viết: “Chúng tôi có thể thấy rằng đối với số lượng token tương đương, sẽ có sự cải thiện hiệu suất đáng kể với quy mô ngày càng tăng”.
Một câu hỏi thú vị trong tương lai là liệu một chương trình mang tính tổng quát có nguy hiểm hơn các loại chương trình AI khác hay không. Các tác giả dành nhiều thời gian trong bài báo để thảo luận về thực tế rằng có những mối nguy hiểm tiềm ẩn vẫn chưa được hiểu rõ.
Ý tưởng về một chương trình xử lý nhiều nhiệm vụ gợi ý cho người bình thường về khả năng thích ứng của con người, nhưng đó có thể là một hiểu lầm nguy hiểm. Reed và nhóm viết: “Ví dụ: phương án vật lý có thể dẫn đến việc người dùng nhân cách hóa tác nhân, dẫn đến mất niềm tin trong trường hợp hệ thống gặp trục trặc hoặc bị kẻ xấu lợi dụng”.
“Ngoài ra, mặc dù chuyển giao kiến thức giữa các miền thường là mục tiêu trong nghiên cứu ML, nhưng nó có thể tạo ra những kết quả không mong muốn và không mong muốn nếu một số hành vi nhất định (ví dụ như đánh nhau trong trò chơi điện tử) được chuyển sang bối cảnh sai.”
Do đó, họ viết, “Các cân nhắc về đạo đức và an toàn trong việc chuyển giao kiến thức có thể yêu cầu nghiên cứu mới đáng kể khi các hệ thống tổng quát phát triển.”
(Là một lưu ý phụ thú vị, bài báo của Gato sử dụng một sơ đồ để mô tả rủi ro do cựu nhà nghiên cứu AI của Google Margaret Michell và các đồng nghiệp nghĩ ra, được gọi là Thẻ mẫu. Thẻ mẫu đưa ra một bản tóm tắt ngắn gọn về chương trình AI là gì, nó làm gì và những gì Michell đã viết vào năm ngoái rằng cô đã bị buộc rời khỏi Google vì ủng hộ đồng nghiệp cũ của mình, Timnit Gebru, người có mối lo ngại về đạo đức đối với AI đã khiến lãnh đạo AI của Google gặp khó khăn.)
Gato hoàn toàn không phải là duy nhất trong xu hướng khái quát hóa của nó. Nó là một phần của xu hướng khái quát hóa rộng rãi và các mô hình lớn hơn sử dụng nhiều mã lực. Thế giới lần đầu tiên được chứng kiến sự nghiêng về hướng này của Google vào mùa hè năm ngoái, với mạng thần kinh “Người nhận thức” của Google kết hợp các tác vụ Biến đổi văn bản với hình ảnh, âm thanh và tọa độ không gian LiDAR.
Ngoài ra: Siêu mẫu của Google: DeepMind Perceiver là một bước trên con đường trở thành một cỗ máy AI có thể xử lý mọi thứ và mọi thứ
Trong số các đồng nghiệp của nó có PaLM, Mô hình ngôn ngữ con đường, được các nhà khoa học của Google giới thiệu vào năm nay, một mô hình tham số 540 tỷ sử dụng công nghệ mới để điều phối hàng nghìn chip, được gọi là Con đường, cũng được phát minh tại Google. Một mạng thần kinh được Meta phát hành vào tháng 2, có tên là “dataXNUMXvec”, sử dụng Transformers cho dữ liệu hình ảnh, dạng sóng âm thanh giọng nói và biểu diễn ngôn ngữ văn bản, tất cả trong một.
Có vẻ như điểm mới của Gato là ý định sử dụng AI cho các nhiệm vụ không phải robot và đẩy nó vào lĩnh vực robot.
Những người tạo ra Gato, ghi nhận những thành tựu của Pathways và các phương pháp tiếp cận tổng quát khác, nhận thấy thành tựu cuối cùng về AI có thể hoạt động trong thế giới thực, với bất kỳ loại nhiệm vụ nào.
“Công việc trong tương lai nên xem xét cách hợp nhất các khả năng văn bản này thành một tác nhân tổng quát hoàn toàn, cũng có thể hoạt động theo thời gian thực trong thế giới thực, trong các môi trường và phương án đa dạng.”
Khi đó, bạn có thể coi Gato là một bước quan trọng trên con đường giải quyết vấn đề khó khăn nhất của AI, đó là robot.
