
DeepMind's 'Gato' is middelmatig, dus waarom hebben ze het gebouwd?


Het 'Gato'-neurale netwerk van DeepMind blinkt uit in tal van taken, waaronder het besturen van robotarmen die blokken stapelen, het spelen van Atari 2600-spellen en het ondertitelen van afbeeldingen.
DeepMind
De wereld is gewend aan de krantenkoppen over de nieuwste doorbraak van deep learning-vormen van kunstmatige intelligentie. De nieuwste prestatie van de DeepMind-divisie van Google kan echter worden samengevat als: “Eén AI-programma dat in veel dingen matig werk doet.”
Gato, zoals het programma van DeepMind heet, werd deze week onthuld als een zogenaamd multimodaal programma, een programma dat videogames kan spelen, chatten, composities kan schrijven, afbeeldingen kan ondertitelen en een robotarm kan besturen die blokken stapelt. Het is één neuraal netwerk dat met meerdere soorten gegevens kan werken om meerdere soorten taken uit te voeren.
“Met een enkele set gewichten kan Gato een dialoog aangaan, afbeeldingen ondertitelen, blokken stapelen met een echte robotarm, beter presteren dan mensen bij het spelen van Atari-spellen, navigeren in gesimuleerde 3D-omgevingen, instructies volgen en meer”, schrijft hoofdauteur Scott Reed en collega’s in hun artikel ‘A Generalist Agent’, geplaatst op de Arxiv preprint-server.
Mede-oprichter van DeepMind, Demis Hassabis, juichte het team toe: roepen in een tweet, “Onze meest algemene agent tot nu toe !! Fantastisch werk van het team!”
Ook: Een nieuw experiment: kent AI echt katten of honden – of zoiets?
Het enige addertje onder het gras is dat Gato eigenlijk niet zo goed is in verschillende taken.
Aan de ene kant kan het programma beter presteren dan een speciaal machine learning-programma bij het besturen van een robotachtige Sawyer-arm die blokken stapelt. Aan de andere kant produceert het bijschriften voor afbeeldingen die in veel gevallen behoorlijk slecht zijn. Het vermogen om een standaardchatdialoog met een menselijke gesprekspartner te voeren is eveneens middelmatig en lokt soms tegenstrijdige en onzinnige uitingen uit.
En het spelen van Atari 2600-videogames valt onder dat van de meeste speciale ML-programma's die zijn ontworpen om te concurreren in de benchmark Arcade leeromgeving.
Populair nu
Waarom zou je een programma maken dat sommige dingen redelijk goed doet en een heleboel andere dingen niet zo goed? Precedent en verwachting, aldus de auteurs.
Er bestaat een precedent voor meer algemene soorten programma's die de state-of-the-art op het gebied van AI worden, en er wordt verwacht dat steeds grotere hoeveelheden rekenkracht in de toekomst de tekortkomingen zullen goedmaken.
Algemeenheid kan de neiging hebben om te zegevieren in AI. Zoals de auteurs opmerken, onder verwijzing naar AI-wetenschapper Richard Sutton: “Historisch gezien hebben generieke modellen die beter zijn in het benutten van berekeningen uiteindelijk ook de neiging om meer gespecialiseerde domeinspecifieke benaderingen in te halen.”
Zoals Sutton schreef in zijn eigen blogpost“De grootste les die uit zeventig jaar AI-onderzoek kan worden getrokken, is dat algemene methoden die gebruik maken van berekeningen uiteindelijk het meest effectief zijn, en met een ruime marge.”
In een formele stelling schrijven Reed en team dat “we hier de hypothese testen dat het trainen van een agent die over het algemeen bekwaam is voor een groot aantal taken mogelijk is; en dat deze algemene agent met weinig extra gegevens kan worden aangepast om een nog groter aantal taken uit te voeren.”
Ook: Meta's AI-held LeCun verkent de energiegrens van deep learning
Het model is in dit geval inderdaad heel algemeen. Het is een versie van de Transformer, het dominante soort op aandacht gebaseerde model dat de basis is geworden van talloze programma's, waaronder GPT-3. Een transformator modelleert de waarschijnlijkheid van een bepaald element, gegeven de elementen eromheen, zoals woorden in een zin.
In het geval van Gato kunnen de DeepMind-wetenschappers dezelfde voorwaardelijke waarschijnlijkheidszoekopdracht gebruiken op talloze gegevenstypen.
Zoals Reed en collega's de taak van het trainen van Gato beschrijven:
Tijdens de trainingsfase van Gato worden gegevens van verschillende taken en modaliteiten geserialiseerd in een platte reeks tokens, gegroepeerd en verwerkt door een neuraal transformatornetwerk, vergelijkbaar met een groot taalmodel. Het verlies wordt gemaskeerd zodat Gato alleen actie- en tekstdoelen voorspelt.
Met andere woorden, Gato behandelt tokens niet anders, of het nu woorden zijn in een chat of bewegingsvectoren in een blokstapeloefening. Het is allemaal hetzelfde.
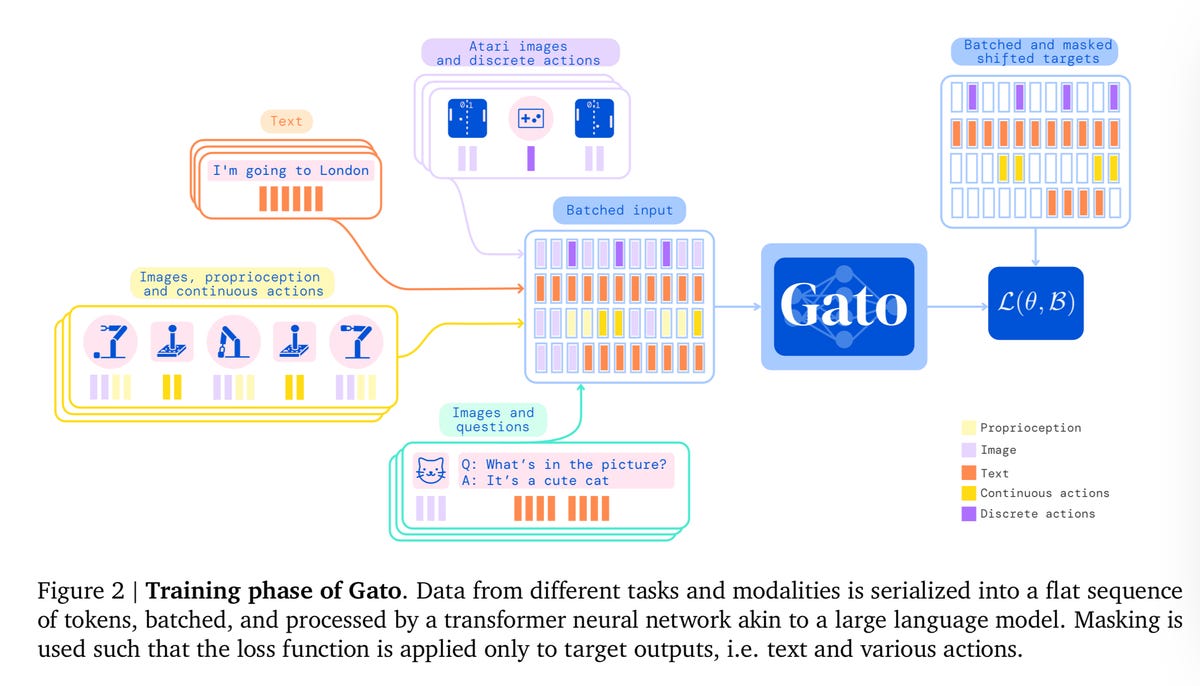
Gato-trainingsscenario.
Riet et al. 2022
In de hypothese van Reed en zijn team ligt een logisch gevolg verborgen, namelijk dat uiteindelijk steeds meer rekenkracht zal winnen. Op dit moment wordt Gato beperkt door de reactietijd van een Sawyer-robotarm die het stapelen van blokken doet. Met 1.18 miljard netwerkparameters is Gato veel kleiner dan zeer grote AI-modellen zoals GPT-3. Naarmate deep learning-modellen groter worden, leidt het uitvoeren van gevolgtrekkingen tot latentie die kan mislukken in de niet-deterministische wereld van een echte robot.
Maar Reed en collega's verwachten dat die limiet zal worden overschreden naarmate AI-hardware sneller wordt verwerkt.
“We concentreren onze training op het werkpunt van modelschaal dat real-time controle van robots uit de echte wereld mogelijk maakt, momenteel rond de 1.2 miljard parameters in het geval van Gato”, schreven ze. “Naarmate de hardware- en modelarchitecturen verbeteren, zal dit werkingspunt op natuurlijke wijze de haalbare modelomvang vergroten, waardoor generalistische modellen hogerop in de curve van de schaalwet terechtkomen.”
Daarom is Gato in werkelijkheid een model voor hoe schaalgrootte de belangrijkste vector voor de ontwikkeling van machine learning zal blijven, door algemene modellen steeds groter te maken. Groter is beter, met andere woorden.
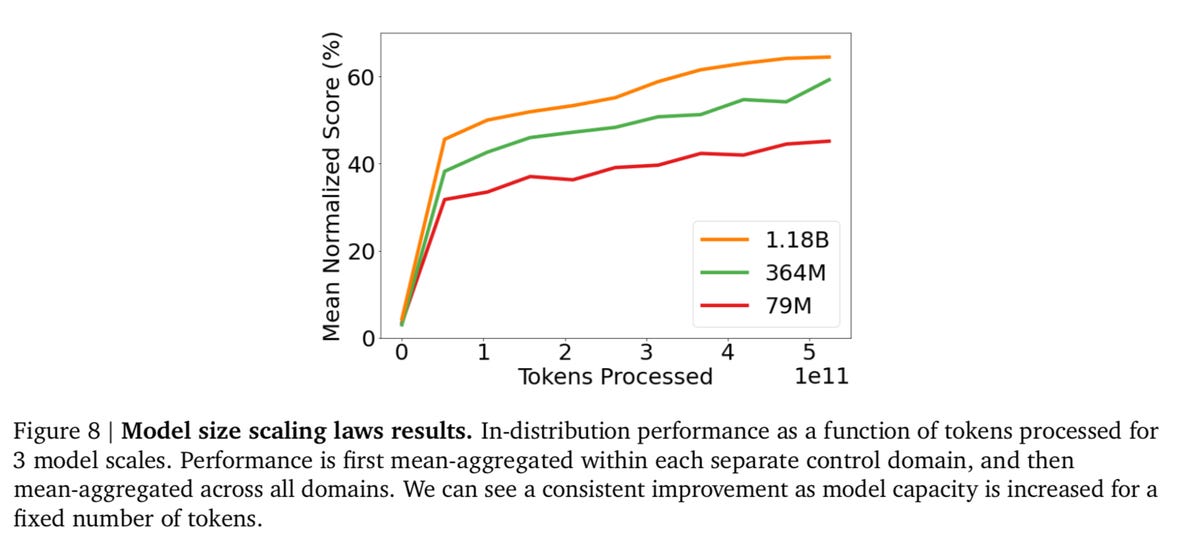
Gato wordt beter naarmate de omvang van het neurale netwerk in parameters toeneemt.
Riet et al. 2022
En de auteurs hebben hier enig bewijs voor. Gato lijkt beter te worden naarmate het groter wordt. Ze vergelijken de gemiddelde scores van alle benchmarktaken voor drie modelgroottes op basis van parameters, 79 miljoen, 364 miljoen, en het hoofdmodel, 1.18 miljard. “We kunnen zien dat er bij een gelijkwaardig aantal tokens een aanzienlijke prestatieverbetering is bij grotere schaal”, schrijven de auteurs.
Een interessante toekomstige vraag is of een programma dat generalistisch is gevaarlijker is dan andere soorten AI-programma's. De auteurs besteden veel tijd aan het bespreken van het feit dat er potentiële gevaren zijn die nog niet goed worden begrepen.
Het idee van een programma dat meerdere taken afhandelt, suggereert voor de leek een soort menselijk aanpassingsvermogen, maar dat kan een gevaarlijke misvatting zijn. “Fysieke belichaming zou er bijvoorbeeld toe kunnen leiden dat gebruikers de agent antropomorfiseren, wat leidt tot misplaatst vertrouwen in het geval van een slecht functionerend systeem, of misbruikt kan worden door slechte acteurs”, schrijven Reed en zijn team.
“Hoewel domeinoverschrijdende kennisoverdracht vaak een doel is in ML-onderzoek, kan dit bovendien onverwachte en ongewenste resultaten opleveren als bepaald gedrag (bijvoorbeeld vechten in arcadespellen) naar de verkeerde context wordt overgebracht.”
Daarom schrijven ze: “De ethische en veiligheidsoverwegingen van kennisoverdracht kunnen substantieel nieuw onderzoek vereisen naarmate generalistische systemen zich ontwikkelen.”
(Als een interessante kanttekening: het Gato-artikel maakt gebruik van een schema om risico's te beschrijven, bedacht door voormalig Google AI-onderzoeker Margaret Michell en collega's, genaamd Model Cards. Model Cards geven een beknopte samenvatting van wat een AI-programma is, wat het doet en wat factoren beïnvloeden de werking ervan. Michell schreef vorig jaar dat ze uit Google werd gedwongen omdat ze haar voormalige collega Timnit Gebru steunde, wiens ethische zorgen over AI in strijd waren met het AI-leiderschap van Google.)
Gato is geenszins uniek in zijn generaliserende tendens. Het maakt deel uit van de brede trend naar generalisatie en grotere modellen die enorme hoeveelheden pk's gebruiken. Afgelopen zomer kreeg de wereld voor het eerst te zien hoe Google deze kant op gaat, met het neurale netwerk 'Perceiver' van Google, dat tekst Transformer-taken combineerde met afbeeldingen, geluid en ruimtelijke LiDAR-coördinaten.
Ook: Supermodel van Google: DeepMind Perceiver is een stap op weg naar een AI-machine die alles en nog wat kan verwerken
Een van zijn collega's is PaLM, het Pathways Language Model, dit jaar geïntroduceerd door Google-wetenschappers, een parametermodel van 540 miljard dat gebruik maakt van een nieuwe technologie voor het coördineren van duizenden chips, bekend als Pathways, ook uitgevonden bij Google. Een neuraal netwerk dat in januari door Meta werd uitgebracht, genaamd ‘data2vec’, gebruikt Transformers voor beeldgegevens, spraak-audiogolfvormen en teksttaalrepresentaties in één.
Wat nieuw is aan Gato, zo lijkt het, is de bedoeling om AI die wordt gebruikt voor niet-robotica-taken te gebruiken en deze naar het robotica-rijk te duwen.
De makers van Gato zien, gezien de prestaties van Pathways en andere generalistische benaderingen, de ultieme prestatie in AI die in de echte wereld kan functioneren, met allerlei soorten taken.
“Toekomstig werk zou moeten overwegen hoe deze tekstmogelijkheden kunnen worden verenigd in één volledig generalistische agent die ook in realtime in de echte wereld kan handelen, in diverse omgevingen en uitvoeringsvormen.”
Je zou Gato dus kunnen beschouwen als een belangrijke stap op weg naar het oplossen van het moeilijkste probleem van AI: robotica.
